CLIP-ViT、EVA-CLIP、InternViT、SigLIP、SigLIP2 在 MLLM 中的对比?
好的,我们来深入剖析这些在多模态大模型(MLLM)中至关重要的视觉编码器。
核心概念
这些模型都是用于 MLLM 的视觉编码器(Vision Encoder),其核心任务是将输入的图像转换为高质量的特征向量,以便与语言模型进行交互。它们的共同祖先是 CLIP,通过大规模图文对的对比学习,将图像和文本映射到同一个语义空间。
- CLIP-ViT: 视觉语言预训练的开创者,使用 Vision
Transformer(ViT) 作为图像编码器,通过对比损失(InfoNCE Loss)在海量网络图文对上进行训练,实现了强大的零样本识别能力。 - EVA-CLIP: 对
CLIP训练范式的改进。它主张先对ViT骨干网络进行充分的、纯视觉的自监督预训练(如 Masked Image Modeling, MIM),然后再进行图文对比学习。这旨在获得一个更强大的视觉表征基础。 - InternViT: “大力出奇迹”的典范。通过使用前所未有规模的数据(数十亿级图文对)和模型(高达 60 亿参数),并结合精心设计的混合训练策略,将视觉编码器的性能推向了新的高度。
- SigLIP: 从损失函数入手进行优化。它放弃了
CLIP使用的、依赖于全局负样本的 InfoNCE Loss,转而采用 Sigmoid 函数计算成对的图文相似度损失。这种解耦使得模型对噪声数据更鲁棒,且不依赖于大的 Batch Size。 - SigLIP2: SigLIP 的高效训练版。它提出了一套更优的训练“配方”,包括锁定(lock)图像编码器、使用更轻量的文本编码器、以及渐进式提升分辨率等技巧,在提升性能的同时显著降低了训练成本。
🖼 5 个视觉编码器架构对照
CLIP · 对比预训练原图
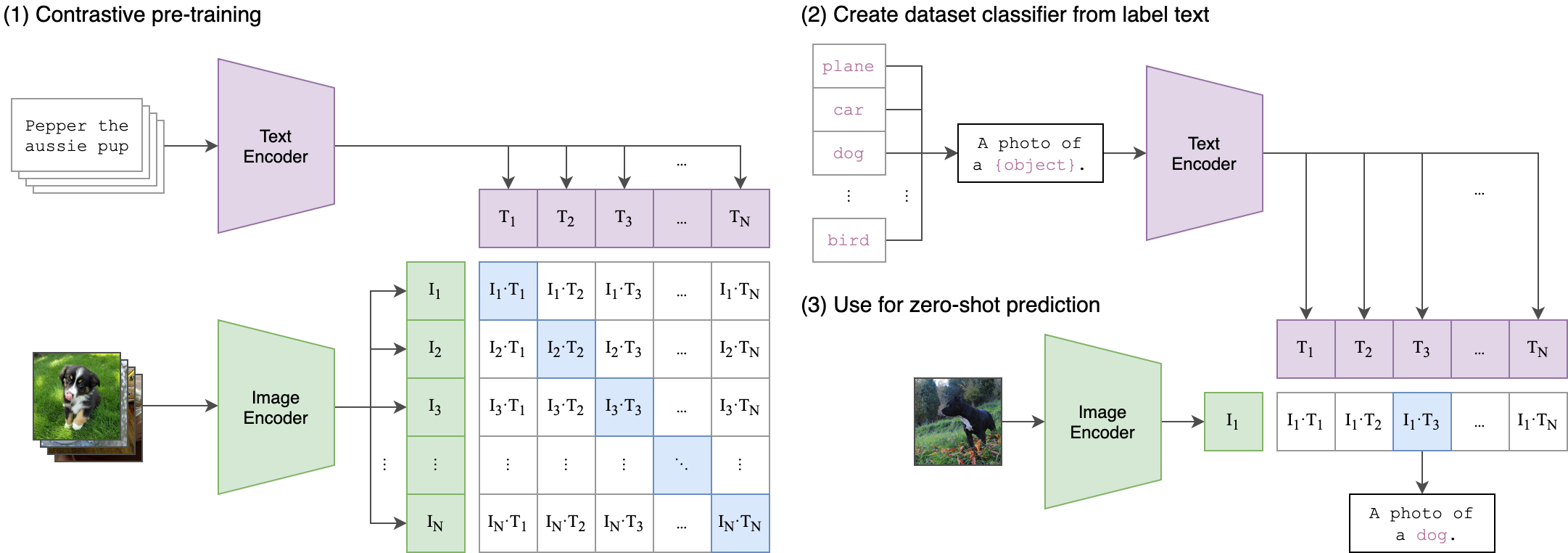
图来自 openai/CLIP 官方仓库(Radford et al. 2021, arxiv 2103.00020)。Image encoder + Text encoder 双塔,N×N 余弦相似度矩阵,对角线 = 正样本,symmetric InfoNCE loss。Zero-shot 分类时把类名套 a photo of a {class} 喂 text encoder 即可。
EVA-CLIP · 大规模 contrastive scaling
图来自 baaivision/EVA 官方仓库(Sun et al. 2023, arxiv 2303.15389)。EVA-CLIP 关键 trick:先用 MIM 预训练 ViT backbone 拿到强视觉表征 → 再做 image-text contrastive,得到比纯 CLIP scaling 更强的特征。EVA-CLIP-18B 是开源最大的 CLIP 模型。
InternViT · 6B 级开源视觉塔
仓库未公开发布独立架构 figure(demo 图为主)。论文 Figure 见原文。
📄 InternVL · arxiv 2312.14238 → · 📄 InternVL-2.5 · arxiv 2412.05271 → · 💻 OpenGVLab/InternVL →
关键设计:InternViT-6B 比同期 CLIP-ViT-L 大 5×;混合预训练目标(CLIP contrastive + ImageNet supervised + MIM);原生支持 dynamic high-resolution(最高 4K×4K tile);中文 OCR / 中文图文任务调优好——国内开源 VLM (InternVL / MiniCPM-V) 默认视觉塔。
SigLIP · sigmoid 替代 softmax
big_vision 仓库未单独发 figure(论文 Figure 2 含 sigmoid vs softmax 对比)。
📄 SigLIP · arxiv 2303.15343 → · 💻 google-research/big_vision →
核心改动:CLIP 的 InfoNCE 要求 batch 内 N 张图和 N 个 caption 互斥配对(softmax 归一化),需要 batch ≥ 32K;SigLIP 把每对 (image, text) 独立做 sigmoid 二分类(正样本 1 / 负样本 0),batch 16K 就足够,多机训练通信量大降。Loss:L = -log σ(z·t) for positive, -log σ(-z·t) for negative。
SigLIP2 · 多语言 + 多分辨率 + decoder loss
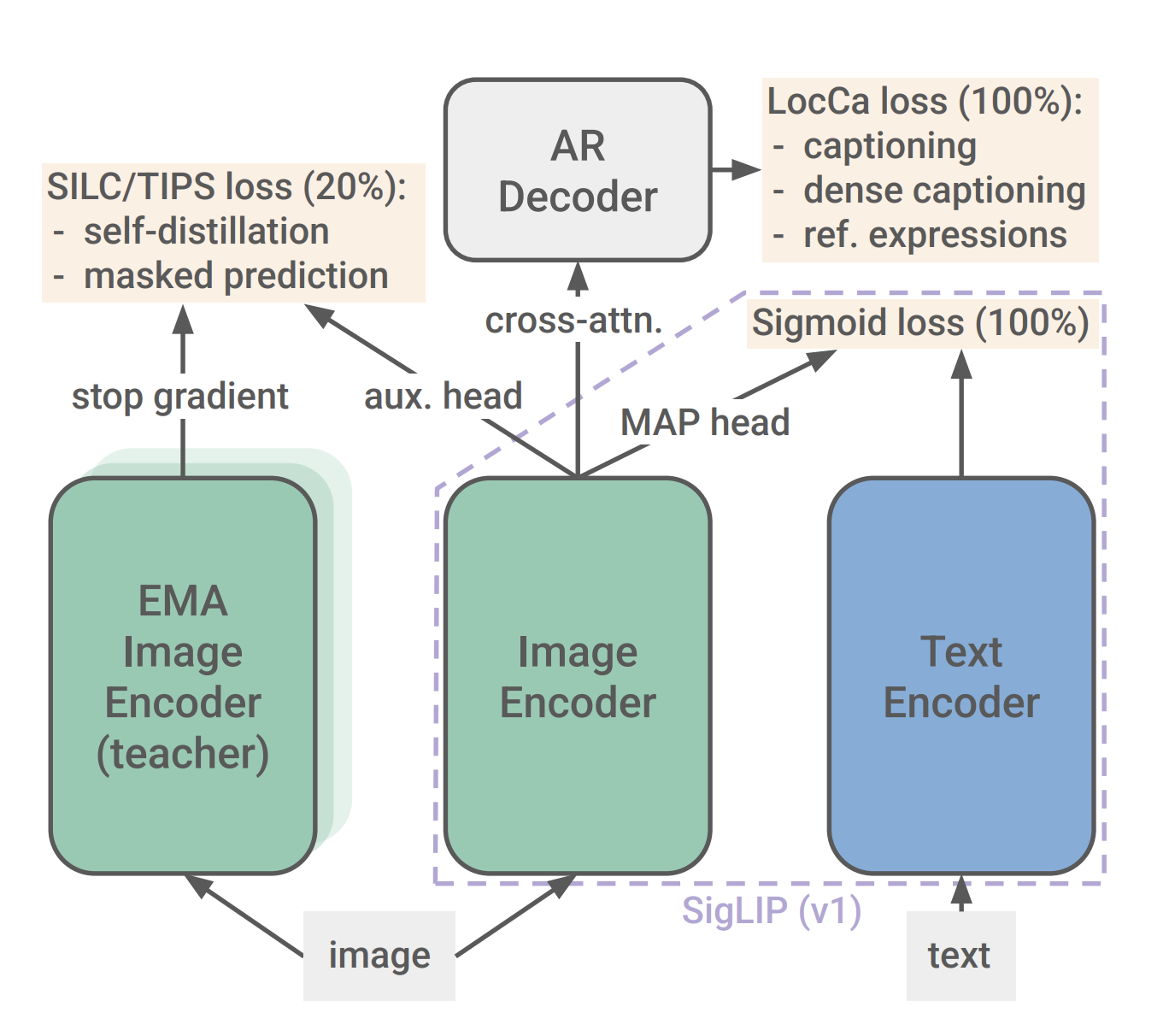
图来自 HuggingFace SigLIP2 blog 官方发布。SigLIP2 在 vision tower 之上挂一个轻量 decoder 做 captioning,把生成式监督加入对比训练——image embedding 现在同时被 sigmoid contrastive 和 captioning loss 拉一遍,下游 dense / spatial 任务明显增强。
📄 SigLIP2 · arxiv 2502.14786 → · 📝 HF blog → · 模型权重 google/siglip2-* on HF →
4 个增量 vs SigLIP:
- Multilingual:训练扩到 200+ 语言(含中日韩),单模型跨语言 zero-shot
- Multi-resolution(NaViT 风格):任意分辨率任意 aspect ratio
- Decoder loss:在 vision tower 之上挂轻量 decoder 做 captioning,把生成式监督加进训练
- SLIP 集成:image-image self-supervised + image-text contrastive 联合训练
总结:MLLM 视觉塔选型
| CLIP-ViT | EVA-CLIP | InternViT | SigLIP | SigLIP2 | |
|---|---|---|---|---|---|
| 规模 | ≤ 1B | ≤ 18B | ≤ 6B | ≤ 1B | ≤ 1B |
| 训练目标 | contrastive | MIM + contrastive | mix (3 loss) | sigmoid pairwise | sigmoid + decoder + SLIP |
| Batch 需求 | 32K+ | 32K+ | 大 | 16K 足够 | 16K |
| 多分辨率 | ✗ | ✗ | ✓ (dynamic tile) | ✗ | ✓ (NaViT) |
| 多语言 | 英文为主 | 英文为主 | 中英都强 | 英文为主 | 200+ 语言 |
| Dense feature | 弱 | 中 | 强 | 中 | 强 |
| 2024+ VLM 用谁 | ↓ 减少 | 部分 | 国内主流 | ↑ 主流 | ↑ 最新主流 |
2024-2025 趋势:SigLIP / SigLIP2 + DINOv2 双塔拼接 成新 VLM (LLaVA-OneVision / InternVL-3 / Qwen2.5-VL) 标配——前者强 text alignment,后者强 dense feature。
原理与推导
所有这些模型的核心都是学习一个图像编码器 和一个文本编码器 ,使得匹配的图文对 在嵌入空间中的余弦相似度尽可能高,不匹配的则尽可能低。
1. CLIP-ViT: 对比学习基石
CLIP 的核心是 InfoNCE (Normalized Temperature-scaled Cross Entropy) Loss,也叫对比损失。
-
原理: 在一个包含 个图文对的 batch 中,对于任意一个图像 ,其对应的文本 是正样本,而 batch 内所有其他的文本 都是负样本。目标是让模型能够从 个文本选项中正确“分类”出与 匹配的 。
-
数学公式: 令 和 分别为归一化后的图像和文本特征向量。它们之间的余弦相似度为 。
对于图像 ,其图到文(Image-to-Text)的损失为:
其中 是一个可学习的温度超参数,用于调节
softmax的锐度。同理,对于文本 ,其文到图(Text-to-Image)的损失为:
整个 batch 的对称损失为:
-
直观解释: InfoNCE Loss 本质上是一个 -分类的交叉熵损失。分母是当前图像与 batch 中所有文本的相似度得分总和,分子是与正样本(正确文本)的相似度得分。优化的目标就是最大化分子的概率。这迫使模型将匹配的图文对拉近,同时将不匹配的推远。
2. EVA-CLIP: 更强的视觉“底座”
EVA-CLIP 的创新不在于对比学习本身,而在于如何获得一个更强大的 ViT 骨干。
-
原理: 它采用两阶段训练范式:
- 阶段一:视觉自监督预训练 (MIM)。使用类似 BEiT 或 MAE 的掩码图像建模(Masked Image Modeling)任务对
ViT进行预训练。模型需要根据图像的部分可见 patches 重建出被掩码(masked)的 patches 的视觉特征。这强迫模型学习图像的内部结构、纹理和上下文关系,形成高质量的通用的视觉表征。 - 阶段二:图文对比学习。将阶段一预训练好的
ViT作为图像编码器,然后用标准的CLIP对比损失在图文对上进行微调。
- 阶段一:视觉自监督预训练 (MIM)。使用类似 BEiT 或 MAE 的掩码图像建模(Masked Image Modeling)任务对
-
动机: 直接在图文对上从头训练
ViT,模型需要同时学习“看懂图像”和“对齐文本”两件事。EVA-CLIP 认为,先让模型专心“看懂图像”,学会通用的视觉知识,再来学习与文本对齐,会更高效且效果更好。
3. InternViT: 规模化的力量
InternViT 的核心是证明了 Scaling Law 在视觉语言预训练中的巨大威力。
-
原理: 其贡献主要在工程和数据层面,而非算法创新。
- 超大规模数据: 构建了一个包含数十亿级别图文对的、经过精细清洗和筛选的数据集 InternData。
- 超大模型: 将
ViT模型的参数量扩展到前所未有的 60 亿。 - 混合训练策略: 采用多阶段、多任务的训练流程,融合了有监督学习(如 ImageNet 分类)、自监督学习(MIM)和图文对比学习,以保证超大模型训练的稳定性和最终性能。
-
结论: 当数据量和模型大小达到一定阈值后,即使使用相对经典的算法,也能涌现出惊人的性能。
4. SigLIP: 优雅的损失函数革新
SigLIP 挑战了 CLIP 的 InfoNCE Loss,认为其存在两个问题:1) 对 batch 内所有负样本进行归一化,计算复杂且对大 batch 敏感;2) 对噪声标签(错误的图文对)惩罚过重。
-
原理: SigLIP 将问题从“多分类”转化为“多标签二分类”。对于一个图像 ,它与配对文本 的关系是“正”,与所有其他文本 的关系都是“负”。每个图文对 都被独立判断。
-
数学公式: 它使用 Sigmoid 函数 来计算每个图文对匹配的概率。损失函数是所有图文对的二元交叉熵之和。
为了增强表达能力,SigLIP 还在相似度计算中加入了可学习的缩放因子 和偏置 :。
-
信息论解释: InfoNCE 假设每个图像在 batch 中只有一个正确的文本配对,这在充满噪声的网络数据中往往不成立。SigLIP 则允许一个图像可能与多个文本(语义上)相关,也可能与标注的“正样本”其实不相关。这种“软”假设使其对噪声更具鲁棒性。同时,由于损失是成对计算的,不再有全局归一化项,因此它不强依赖于巨大的 batch size 来提供足够的负样本。
5. SigLIP2: 高效训练的“秘方”
SigLIP2 继承了 SigLIP 的损失函数,并探索了一套极致高效的训练策略。
-
原理:
- 锁定图像编码器 (Locked-image Tuning): 在训练初期,冻结一个已经在纯视觉任务(如 ImageNet-21k)上预训练好的
ViT编码器。只训练文本编码器和多模态投射层。这极大地稳定了训练过程,并降低了计算/显存开销。在训练后期,再将图像编码器解冻进行端到端微调。 - 简化文本编码器: 实验发现,使用一个非常简单的文本编码器(如 Bag-of-Words)也能取得不错的效果,进一步节省了计算资源。
- 渐进式分辨率: 训练从低分辨率图像开始,随着训练的进行逐步提高分辨率。这是一种经典的加速视觉模型训练的技巧。
- 锁定图像编码器 (Locked-image Tuning): 在训练初期,冻结一个已经在纯视觉任务(如 ImageNet-21k)上预训练好的
-
动机: 旨在回答一个问题:“在有限的计算预算下,如何最大化视觉语言模型的性能?” SigLIP2 的答案是:用好的损失函数(Sigmoid),并找到一条计算开销和最终性能之间的最佳路径。
工程实践
在为 MLLM 选择或构建视觉编码器时,这些模型的差异带来了不同的考量:
-
使用场景与选择:
- 从零开始训练,预算有限: SigLIP/SigLIP2 是首选。Sigmoid 损失对 batch size 不敏感,允许你在较少的 GPU 上进行训练。SigLIP2 的训练秘方更是为高效训练量身定制。
- 追求极致性能,资源充足: 可以借鉴 InternViT 的思路,即尽可能扩大模型和数据规模。或者使用 EVA-CLIP 的范式,先用 MIM 对一个巨大的
ViT进行预训练,再进行对比学习。 - 快速搭建原型/使用现有模型: 直接使用社区中开源的、强大的预训练模型,如 OpenCLIP 提供的各种尺寸的 CLIP-ViT,或者 Google 开源的 SigLIP 模型。这些模型是久经考验的强大基线。例如,LLaVA-1.5 的一个关键升级就是将其视觉编码器从标准 CLIP-ViT-L/14 换成了一个在更大数据集上训练的同结构模型,带来了显著的性能提升。
-
超参数选择:
CLIP的温度 : 这是一个非常关键的超参数。通常设为可学习的参数。它的值影响着模型对难负样本的关注程度。- SigLIP 的 batch size: 虽然 SigLIP 对 batch size 不敏感,但一个足够大的 batch 仍然有助于提供多样化的负样本,从而稳定训练。不过,相比 InfoNCE,其需求已大大降低。
- EVA-CLIP 的两阶段训练: 如何平衡两个阶段的训练时长和资源是一个关键。通常,第一阶段的 MIM 预训练需要大量的计算,但这是一次性的投入,可以为后续多个实验复用。
-
性能 / 显存 / 吞吐 的权衡:
- 模型大小: InternViT-6B 这样的模型性能强大,但推理和训练都需要大量的显存和计算卡,并且需要复杂的并行策略(张量并行、流水线并行)。对于多数应用,选择一个中等大小(如 ViT-L 或 ViT-H)的模型是更实际的折中。
- 训练范式: SigLIP2 的锁定图像编码器策略在训练初期极大降低了显存占用和计算量,因为反向传播不需要经过庞大的
ViT。 - 损失函数: Sigmoid 损失的计算比 InfoNCE 更简单,因为它避免了全局的
softmax计算,尤其是在多卡同步的场景下,可以减少通信开销。
常见误区与边界情况
-
误区一:“
CLIP的性能完全来自对比损失”- 辨析: 这是不全面的。
CLIP的成功是三位一体的:(1) 简洁有效的对比损失;(2) 可扩展的ViT架构;(3) 海量的、带有自然噪声的网络图文数据。三者缺一不可。数据的规模和多样性是其强大泛化能力的关键。
- 辨析: 这是不全面的。
-
误区二:“EVA-CLIP 就是先做 MAE 再做
CLIP”- 辨析: 基本正确,但细节很重要。EVA-CLIP 的核心洞见是解耦视觉表征学习和图文对齐学习。它证明了专门为视觉设计的自监督任务(MIM)可以为下游的图文任务提供一个远优于“从零开始”的起点。
-
误区三:“SigLIP 彻底解决了噪声问题”
- 辨析: SigLIP 极大地缓解了噪声问题,但并未彻底解决。它通过将损失计算解耦,使得单个错误的图文对不会“污染”整个 batch 的梯度信号。但如果数据集中噪声比例过高,模型仍然会学到错误的关联。数据清洗和筛选始终是重要的一环。
-
常见面试追问:
- 问: “为什么 InfoNCE Loss 需要大 batch size,而 SigLIP 不需要?”
- 答: InfoNCE 的分母项 包含了 batch 内所有的负样本。一个大的 batch size 意味着更多的负样本,这增加了采样到“难负样本”(与正样本在语义上接近但不匹配的样本)的概率,从而给模型提供更有信息量的梯度信号。而 SigLIP 对每个负样本独立计算损失,其性能不直接依赖于一次性看到多少负样本。
- 问: “如果你要为一个 MLLM 设计视觉部分,但你的训练数据非常嘈杂,你会选择哪种技术路线?”
- 答: 我会优先选择 SigLIP 作为损失函数,因为它对噪声标签的鲁棒性更好。在训练策略上,我会借鉴 SigLIP2 的方法,先找一个在干净数据集(如 ImageNet)上预训练好的
ViT模型并冻结它,只训练文本塔和对齐层。这样可以利用干净数据学到的通用视觉特征,避免在早期被噪声文本“带偏”,等模型对语言有一定理解后再进行端到端微调。 - 问: “InternViT 和 EVA-CLIP 都强调了视觉预训练,它们有什么不同?”
- 答: 核心理念不同。EVA-CLIP 强调的是训练范式的先进性,即“先纯视觉自监督,再图文对比”的两阶段方法。InternViT 强调的是规模化的力量,它将数据、模型、计算资源推到极致,其训练策略(混合多种任务)主要是为了服务于超大规模训练的稳定性和有效性。可以理解为,EVA-CLIP 是在寻找更聪明的学习方法,而 InternViT 是在验证力大砖飞的可行性。在实践中,两者可以结合,例如用 EVA-CLIP 的范式来训练一个 InternViT 规模的模型。
- CLIP: Learning Transferable Visual Representations· 2021看站内总结 →
4 亿图文对 + 对比学习——零样本图像分类能和监督训练的 ResNet 匹敌。
- LLaVA: Visual Instruction Tuning· 2023看站内总结 →
CLIP-ViT + LLaMA + 一个 linear projection——简单但有效的开源 VLM 基线。
- MAE: Masked Autoencoders Are Scalable Vision Learners· 2021看站内总结 →
BERT-for-vision:mask 掉 75% patch、不对称 encoder/decoder、像素级重建——把 ViT 的 SSL 推到生产可用。
- DINOv2: Learning Robust Visual Features without Supervision· 2024看站内总结 →
把 DINO 的 self-distillation + 142M 精挑数据 + iBOT 风格 patch-level loss 推到 ViT-g (1.1B),产出可直接用于多种下游任务的「通用视觉特征」。