从 SIFT/HOG → AlexNet → ResNet → ViT 的视觉表征演进?
核心概念
视觉表征(Visual Representation)是指将原始的像素级图像数据,通过一系列变换,映射到一个能够揭示图像语义内容、便于后续任务(如分类、检测)处理的特征空间的过程。其演进的核心主线是从手工设计的局部特征(Hand-crafted Features)到端到端学习的、从局部到全局的层级化特征(Learned Hierarchical Features)。
- SIFT/HOG:代表了经典计算机视觉时代的巅峰,依赖于人类专家对图像统计特性的深刻理解,设计出对光照、旋转、尺度等变化具有不变性的局部特征描述子。
- AlexNet:标志着深度学习时代的开启。它证明了通过大规模数据驱动,一个深层卷积神经网络(CNN)可以自动学习到比手工特征更强大、更具判别力的层级化特征,实现了端到端的学习范式。
- ResNet:解决了深度神经网络的“退化”问题,通过引入残差连接(Residual Connection),使得训练数百甚至上千层的网络成为可能。这让模型能够学习到更深、更抽象的特征表示,极大地提升了模型性能。
ViT(VisionTransformer):借鉴了自然语言处理领域的Transformer模型,将图像视为一系列“补丁”(Patches)组成的序列。它摒弃了 CNN 固有的局部归纳偏置(Inductive Bias),利用自注意力机制(Self-Attention)直接建模图像中所有补丁之间的长距离依赖关系,实现了全局感受野,在超大规模数据集上展现出卓越的性能。
🖼 视觉表征演进 · 4 个时代的代表性架构
ViT · 官方架构图
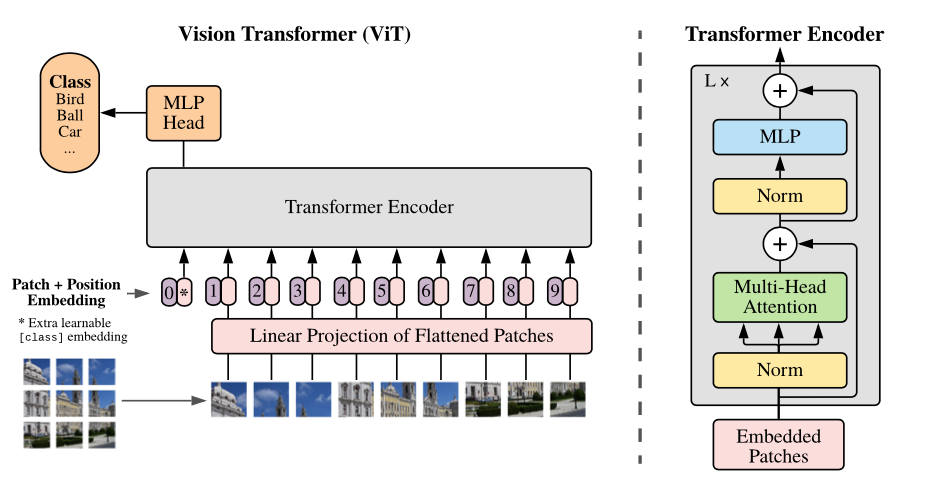
图来自 google-research/vision_transformer 官方仓库(Dosovitskiy et al. 2020, arxiv 2010.11929)。把图像切成 16×16 patch → 线性投影 + position embedding + [CLS] token → 标准 Transformer encoder → 用 [CLS] 输出做分类。
📄 ViT paper · arxiv 2010.11929 → · 📄 ResNet paper · arxiv 1512.03385 → · 📄 AlexNet paper · NeurIPS 2012 → · 📄 HOG paper · CVPR 2005 →
上方 3 张概念图(HOG / AlexNet / ResNet)是站内整理的精简流程图,灵感来自论文原图但非像素复刻;
ViT是 Google 官方仓库的原图。
原理与推导
1. SIFT/HOG (手工特征时代)
这类方法的核心是基于图像梯度信息构建特征描述子。以 HOG (Histogram of Oriented Gradients) 为例,其原理是:物体局部形状和外观可以被其梯度或边缘的方向密度分布很好地描述。
算法步骤(以HOG为例):
- 梯度计算:计算图像每个像素点的水平和垂直梯度,得到梯度的大小和方向。 , 幅度: 方向:
- 构建方向直方图:将图像划分为小的单元格(Cell,如 8x8 像素),为每个 Cell 计算一个梯度方向直方图。每个像素根据其梯度方向和幅度,投票给对应的直方图 bin。
- 块(Block)内归一化:将几个 Cell 组合成一个更大的块(Block,如 2x2 个 Cell),将块内所有 Cell 的直方图拼接成一个长向量,然后对该向量进行归一化(如 L2-norm)。 动机:归一化操作能有效降低光照和对比度变化带来的影响,增强特征的鲁棒性。
- 特征向量:将所有 Block 的归一化后的向量拼接起来,形成最终的 HOG 特征描述子。
直观解释:HOG 忽略了颜色信息,专注于边缘方向的统计,这使得它对光照变化不敏感。它捕捉的是一种“轮廓”信息。SIFT 原理类似,但增加了关键点检测和尺度空间分析,使其具有尺度和旋转不变性。
2. AlexNet (CNN 时代)
CNN 的核心是卷积操作,它通过共享权重的滤波器(Kernel)在输入数据上滑动,实现特征提取。
原理与公式: 对于一个二维输入特征图 和一个卷积核 ,其输出特征图 在位置 的值计算如下: 其中 是偏置项。
核心思想:
- 局部连接 (Local Connectivity):每个神经元只与前一层的一个局部区域(感受野)相连,这符合图像的空间局部性。
- 参数共享 (Parameter Sharing):一个卷积核在整个图像上滑动,其权重是共享的。这大大减少了模型参数量,并使网络具有平移等变性 (Translation Equivariance),即输入平移,输出也相应平移。
- 层级化特征:浅层网络学习到边、角、颜色等低级特征,深层网络则组合这些低级特征,形成纹理、物体部件乃至整个物体等高级抽象特征。
复杂度:对于一个卷积层,时间复杂度约为 ,其中 是特征图高宽, 是通道数, 是卷积核大小。
3. ResNet (超深网络时代)
为了解决网络加深后出现的退化问题(Degradation Problem,即深层网络在训练集上的表现反而比浅层网络差),ResNet 引入了残差学习。
原理与推导: 假设我们期望一个网络层学习的映射为 。传统网络直接学习 ,而 ResNet 学习一个残差函数 ,则原始映射变为 。
这个 的连接被称为“捷径连接”或“跳跃连接”(Skip/Shortcut Connection)。
梯度反向传播推导: 考虑一个残差块的输出 和损失函数 。根据链式法则,损失对输入 的梯度为:
动机分析:
- 梯度高速公路:公式中的
+1项确保了即使残差分支 的梯度很小甚至为零(梯度消失),梯度仍然可以无衰减地通过跳跃连接反向传播到浅层网络。这创建了一条“梯度高速公路”,极大地缓解了梯度消失问题。 - 简化学习目标:如果恒等映射 () 是最优解,传统网络需要将权重学习到趋近于 0,这比较困难。而对于 ResNet,只需将残差函数 的权重学习到 0 即可,这远比学习一个恒等变换容易。网络可以专注于学习对恒等映射的“修正”。
4. ViT (Transformer 时代)
ViT 将 Transformer 架构应用于视觉任务,其核心是自注意力机制。
原理与步骤:
- 图像分块 (Image to Patches):将输入图像 拆分成 个固定大小的图像块(Patches),,其中 是每个块的边长。每个块被展平为一维向量。
- 块嵌入 (Patch
Embedding):通过一个线性投影层将每个展平的块向量映射到 维的嵌入空间。为了保留位置信息,需要加上可学习的位置嵌入 (Positional Embeddings)。 TransformerEncoder:将嵌入向量序列输入到标准的TransformerEncoder 中。Encoder 由多层堆叠而成,每层包含:- 多头自注意力 (Multi-Head
Self-Attention, MHSA) - 前馈网络 (Feed-Forward Network, FFN)
- 多头自注意力 (Multi-Head
自注意力机制 (Self-Attention):
对于输入序列中的每个元素(Patch Embedding),我们通过三个独立的线性变换生成 Query ()、Key ()、Value () 向量。
直观解释:
- 计算了每个 Query(代表当前块)与所有 Key(代表所有块)之间的“相似度”或“关联度”。
- 是一个缩放因子,用于防止点积结果过大导致
softmax进入饱和区,稳定梯度。 - 将相似度分数转换为权重,所有权重的和为 1。
- 最后,将这些权重应用于 Value 向量进行加权求和,得到该 Query 的新表示。这个新表示融合了图像中所有其他块的信息,权重由它们与当前块的关联度决定。
动机:CNN 的卷积操作具有固定的、局部的感受野。而自注意力机制的感受野是全局的,它允许网络在单层内就直接建模图像中任意两个块之间的长距离依赖关系,这对于理解复杂的场景和物体关系非常有帮助。
复杂度:自注意力机制的时间和空间复杂度为 ,其中 是序列长度(即图像块的数量)。这使得它在处理高分辨率图像时计算成本非常高。
代码实现
下面以 PyTorch 实现 ResNet 的核心组件 残差块 (Residual Block) 为例。
1import torch2import torch.nn as nn34class ResidualBlock(nn.Module):5 """6 一个标准的 ResNet 残差块 (Basic Block for ResNet18/34)7 包含两个 3x3 卷积层。8 """9 def __init__(self, in_channels, out_channels, stride=1):10 super(ResidualBlock, self).__init__()1112 # 残差函数 F(x) 的主分支13 # 第一个卷积层,可能通过 stride 实现下采样14 self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)15 # 为什么用 BatchNorm:标准化每层输出,使其均值为0,方差为1。这能加速收敛,稳定训练,并允许使用更高的学习率。16 self.bn1 = nn.BatchNorm2d(out_channels)17 # 为什么用 ReLU:引入非线性,使得网络可以学习更复杂的函数。18 self.relu = nn.ReLU(inplace=True)1920 # 第二个卷积层21 self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)22 self.bn2 = nn.BatchNorm2d(out_channels)2324 # 跳跃连接 (Shortcut Connection)25 self.shortcut = nn.Sequential()26 # 为什么需要这个判断:如果输入和输出的维度不匹配(通道数或尺寸不同),27 # 跳跃连接的 x 就无法直接与 F(x) 相加。28 # 此时,需要通过一个 1x1 卷积对 x 进行变换,使其维度匹配。29 if stride != 1 or in_channels != out_channels:30 self.shortcut = nn.Sequential(31 nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),32 nn.BatchNorm2d(out_channels)33 )3435 def forward(self, x):36 # 保存输入,用于最后的相加,这就是恒等映射 x37 identity = self.shortcut(x)3839 # F(x) 的计算过程40 out = self.conv1(x)41 out = self.bn1(out)42 out = self.relu(out)4344 out = self.conv2(out)45 out = self.bn2(out)4647 # 核心步骤:F(x) + x48 # 为什么是加法:加法操作使得梯度可以无衰减地流过恒等分支,形成了“梯度高速公路”。49 out += identity50 out = self.relu(out) # 最后的 ReLU 激活5152 return out5354# --- 示例用法 ---55if __name__ == '__main__':56 # 模拟一个输入张量:batch_size=4, channels=64, height=56, width=5657 input_tensor = torch.randn(4, 64, 56, 56)5859 # 场景1:输入输出维度相同60 print("--- 场景1: 维度不变 ---")61 block_same_dim = ResidualBlock(in_channels=64, out_channels=64, stride=1)62 output_tensor_same = block_same_dim(input_tensor)63 print(f"输入尺寸: {input_tensor.shape}")64 print(f"输出尺寸: {output_tensor_same.shape}\n") # 应该和输入尺寸一样6566 # 场景2:输入输出维度不同 (下采样 + 通道增加)67 print("--- 场景2: 维度变化 (下采样) ---")68 block_downsample = ResidualBlock(in_channels=64, out_channels=128, stride=2)69 output_tensor_down = block_downsample(input_tensor)70 print(f"输入尺寸: {input_tensor.shape}")71 print(f"输出尺寸: {output_tensor_down.shape}") # 高宽减半,通道加倍
工程实践
-
使用场景:
- SIFT/HOG:在算力极其受限的嵌入式设备、对实时性要求极高且场景简单的传统工业视觉任务、或缺乏大量标注数据的项目中,仍有应用价值。例如,用于图像拼接、简单的物体有无判断等。
- ResNet及其变体:是当前计算机视觉任务的“默认基石”和“强大基线”。广泛用于图像分类、目标检测、语义分割等几乎所有视觉任务。当你不确定用什么模型时,从一个预训练的 ResNet 开始通常是最好的选择。
ViT及其变体:在拥有海量数据集(如 ImageNet-21K, JFT-300M)的预训练条件下,ViT在图像分类任务上通常能达到 SOTA(State-of-the-Art)性能。它也逐渐被应用于下游任务,如 DETR(目标检测)、SETR(语义分割)。对于追求极致性能且不计较计算成本和数据量的场景,ViT是首选。
-
超参数选择:
- ResNet:关键在于深度(18, 34, 50, 101, 152层)和宽度(通道数)的选择。ResNet-50 是性能和效率之间的一个甜点。更深的网络(101, 152)性能更强但更慢。对于更深的网络(50层及以上),使用计算效率更高的Bottleneck Block(1x1, 3x3, 1x1卷积组合)。
ViT:关键超参数是Patch Size。小的 Patch Size(如 16x16)能保留更多细节,性能更好,但计算量(序列长度的平方)急剧增加。大的 Patch Size(如 32x32)计算更快,但可能损失性能。这是一个关键的性能/成本权衡点。其他如嵌入维度 D、头数、层数也遵循Transformer的通用设计原则。
-
性能/显存/吞吐权衡:
- CNN (ResNet):计算量与输入分辨率成线性关系,对高分辨率图像更友好。其归纳偏置使其在中小数据集上更数据高效。
ViT:计算量与 Patch 数量(即分辨率的平方)成二次方关系。处理高分辨率图像时,显存和计算开销会成为瓶颈。Hybrid 模型(如 ConvNeXt, CoAtNet)结合了 CNN 的效率和Transformer的全局建模能力,试图取得更好的平衡。
-
调试技巧:
- 训练 ResNet 不收敛时,首先检查
BatchNorm的使用是否正确,以及残差连接的维度匹配逻辑是否有误。 - 训练
ViT性能不佳时,检查位置嵌入是否添加,以及预训练权重的加载是否正确。在小数据集上从头训练ViT效果通常很差,强大的预训练是其成功的关键。
- 训练 ResNet 不收敛时,首先检查
常见误区与边界情况
-
误区1:“ResNet 彻底解决了梯度消失问题。”
- 辨析:ResNet 极大地缓解了梯度消失,但并未彻底解决。梯度仍然会通过残差分支 流动,这部分梯度依然可能消失。是
+1的恒等路径保证了至少有一条通路可以让梯度顺畅回传。Batch Normalization 在稳定训练中也扮演了至关重要的角色。
- 辨析:ResNet 极大地缓解了梯度消失,但并未彻底解决。梯度仍然会通过残差分支 流动,这部分梯度依然可能消失。是
-
误区2:“
ViT因为没有归纳偏置,所以比 CNN 更好。”- 辨析:这是一个双刃剑。缺乏归纳偏置(如局部性、平移等变性)意味着
ViT必须从数据中学习这些基本规则,因此需要海量的数据。在数据量不足时,CNN 的归纳偏置是一种非常有用的先验知识,能帮助模型更快更好地收敛。ViT的优势体现在“暴力美学”上,即当数据规模大到足以淹没先验知识时,其更灵活的全局建模能力才能充分发挥。
- 辨析:这是一个双刃剑。缺乏归纳偏置(如局部性、平移等变性)意味着
-
误区3:“跳跃连接必须是恒等映射。”
- 辨析:只有在输入和输出维度完全一致时,跳跃连接才是严格的恒等映射 。当残差块需要改变特征图的尺寸(通过 stride>1 的卷积)或通道数时,跳跃连接本身也必须进行相应的变换(通常是带 stride 的 1x1 卷积)来匹配维度,否则无法进行元素相加。
-
边界情况与面试追问:
- 问:为什么
ViT需要位置嵌入(PositionalEmbedding)?- 答:自注意力机制是置换不变的(Permutation Invariant)。也就是说,如果打乱输入序列中各个 Patch 的顺序,输出结果将完全相同。这显然不符合图像的结构。位置嵌入向模型注入了关于每个 Patch 原始位置的信息,让模型能够理解图像的空间布局。
- 问:如果给你一个新项目,如何在 ResNet 和
ViT之间选择?- 答:我会基于以下几点考虑:
- 数据规模:如果是中小型数据集(如几万到几十万张图),我会首选预训练的 ResNet。它的归纳偏置使其更数据高效。如果拥有千万级甚至亿级的数据集,我会考虑
ViT,因为它能更好地利用大规模数据。 - 计算资源:
ViT对高分辨率图像的计算和显存需求增长很快。如果项目涉及高清图像且资源有限,CNN 或 Hybrid 架构可能更合适。 - 任务类型:对于分类任务,
ViT表现优异。但在密集预测任务(如分割、检测)上,CNN 架构经过多年发展,拥有非常成熟和高效的设计(如 FPN、U-Net)。虽然ViT也在这些领域取得进展,但 CNN 方案通常更直接、更稳定。 - 预训练模型:评估 Hugging Face 等社区提供的预训练模型。一个在超大数据集上预训练过的
ViT模型,即使在中小规模的下游任务上微调,也可能表现出惊人的性能。
- 数据规模:如果是中小型数据集(如几万到几十万张图),我会首选预训练的 ResNet。它的归纳偏置使其更数据高效。如果拥有千万级甚至亿级的数据集,我会考虑
- 答:我会基于以下几点考虑:
- 问:为什么