Swin Transformer 的 window + shifted window attention?
核心概念
Swin Transformer 的核心是通过一种巧妙的 窗口化自注意力 (Windowed Self-Attention) 机制,将标准 Transformer 对全局依赖关系建模的高计算复杂度,转变为对局部窗口内建模的线性复杂度,从而高效地处理高分辨率图像。为了弥补窗口之间缺乏信息交互的缺陷,它进一步引入了 移位窗口 (Shifted Window) 机制,通过在连续的 Transformer Block 中交替使用常规窗口和移位窗口,实现了跨窗口的信息流动,最终在保持计算效率的同时,构建了具有层级结构的全局感受野。
🖼 层级特征图 vs ViT 单尺度
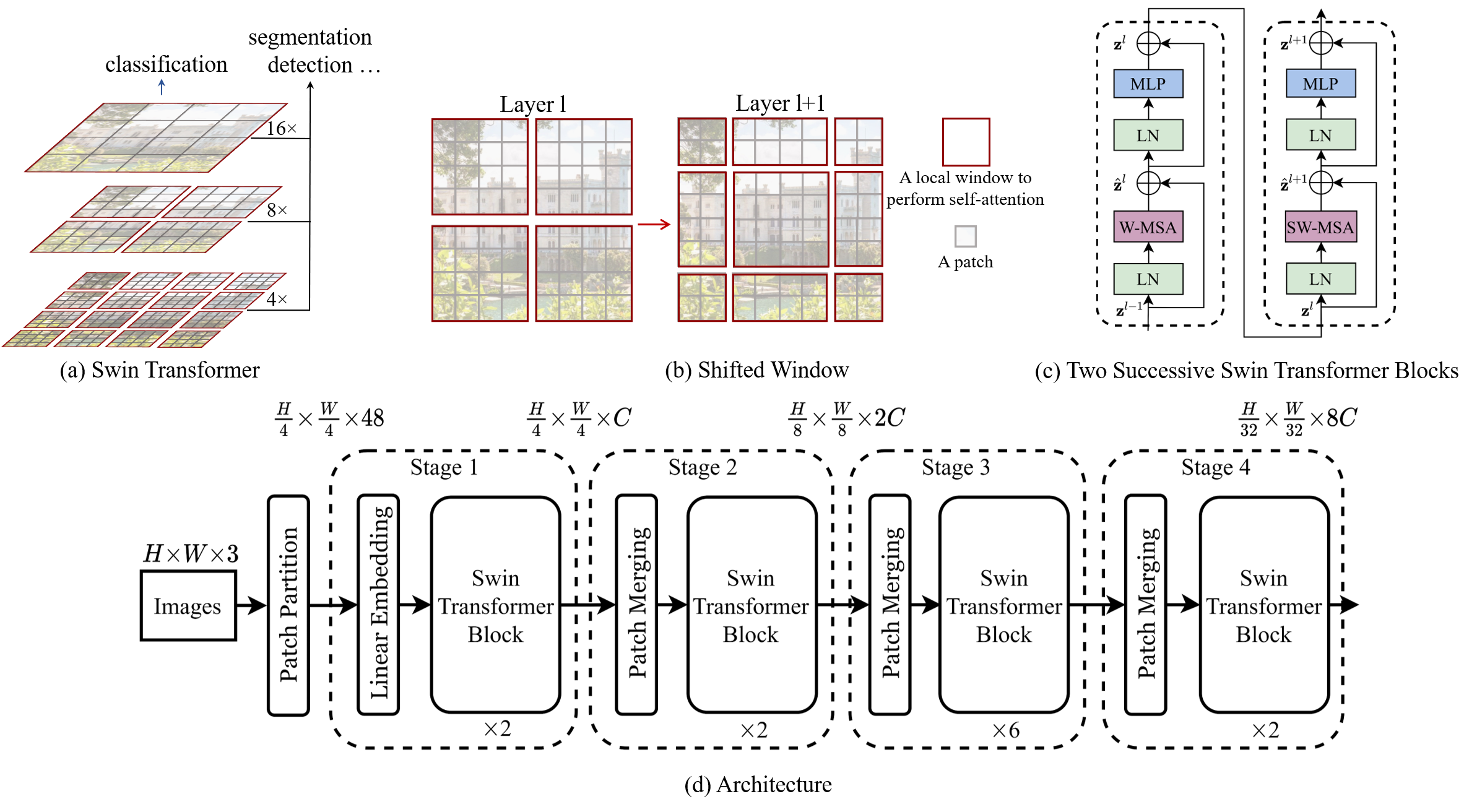
图:左 — Swin 的层级特征图(像 CNN 一样逐层下采样,每层 patch 区域翻倍,能给检测 / 分割提供多尺度特征);右 — ViT 的单层固定尺度,整张图所有 token 互相 attend,复杂度 O(N²)。来自 microsoft/Swin-Transformer。
🪟 Shifted Window 实时动画
Layer L:8×8 token 网格被规则划分为 4 个 4×4 窗口, 每个窗口内部做 self-attention, 复杂度 O(M²·N/M²) = O(N) 线性。 但此时窗口之间互不通信。
核心 trick:上一层窗口分区是规则的,下一层把整个网格向右下平移 ⌊M/2⌋ token,原本被分到不同窗口的相邻 token 现在落进同一窗口里 —— 跨窗口连接建立,感受野逐层扩大。边缘退化的小窗口在工程实现里用 cyclic shift + masked attention 还原成完整 4×4 处理。复杂度仍是 O(M²·N/M²) = O(N) 线性于 token 数。
原理与推导
标准 Vision Transformer (ViT) 将图像展平为一系列 patch (tokens),然后计算所有 token 对之间的自注意力。对于一个包含 个 token 的图像,其计算复杂度为 ,这在 很大时是无法接受的。Swin Transformer 旨在解决这个问题。
1. 窗口内多头自注意力 (W-MSA)
Swin Transformer 首先将图像特征图(Feature Map)划分为一个个不重叠的 窗口 (Window)。假设窗口大小为 。
-
动机: 将全局的注意力计算限制在每个小窗口内部,从而大幅降低计算量。
-
计算: 自注意力只在每个窗口内的 个 token 之间进行计算。
-
复杂度分析:
- 图像大小为 ,通道数为 。
- 窗口大小为 。
- 窗口数量为 。
- 每个窗口内的 token 数量为 。
- 标准自注意力的复杂度为:
- W-MSA 的复杂度为:
- 对比可以发现,W-MSA 的复杂度从 降低到了 。由于 是一个较小的常数(典型值为 7),复杂度与图像大小 呈 线性关系,这是一个巨大的提升。
-
几何解释: 想象在一张大地图上,
ViT允许任何两个地点直接通信,成本高昂。W-MSA 则将地图划分为多个城市(窗口),只允许每个城市内部的地点相互通信,成本大大降低。
2. 移位窗口多头自注意力 (SW-MSA)
W-MSA 的问题在于,窗口之间是隔离的,无法进行信息交换,这会限制模型的感受野和建模能力。
-
动机: 建立相邻窗口之间的连接,实现跨窗口的信息流动。
-
朴素思想: 直接将窗口的划分网格移动一下。例如,在第 层使用常规的窗口划分,在第 层,将窗口网格向右下角移动 个像素。
-
问题: 朴素的移位会产生两个问题:
- 窗口数量增加: 原本 个窗口会变成 个。
- 窗口大小不一: 移位后会产生 , , , 等多种尺寸的窗口,这使得批处理变得非常低效。
-
高效的实现:循环移位 (Cyclic Shift) + 注意力掩码 (Attention Mask) Swin
Transformer提出了一种极为巧妙的等效实现方法,以避免上述问题。- 循环移位: 对特征图进行向左上方的循环移位,移位大小为 。这会将原本在移位后会从左边和上边“掉出去”的区域,移动到右边和下边。
- 常规窗口划分: 在循环移位后的特征图上,执行和 W-MSA 完全一样的 窗口划分。
- 问题与修正: 经过循环移位后,一个 的窗口内可能包含了来自原图中不同区域的子块。例如,一个窗口可能由原图的 A, B, C, D 四个不相邻的区域拼接而成。这些子块在逻辑上不应相互计算注意力。
- 注意力掩码: 为了解决这个问题,需要引入一个掩码 (mask)。在计算注意力分数后、进行 Softmax 之前,将这个掩码加到注意力矩阵上。掩码的作用是:对于那些属于不同原始子区域的 token 对,给它们的注意力分数加上一个极大的负数(如 -100),这样在经过 Softmax 后,它们的注意力权重会趋近于 0,从而阻止了它们之间的信息交互。
- 逆向循环移位: 在计算完 SW-MSA 后,将特征图循环移位回去,恢复其原始的排列顺序,以便送入下一层。
-
几何解释: 为了让城市 A 和城市 B 的人能交流,不是建一条昂贵的跨城高铁,而是用“魔法”把城市 A 的东区和城市 B 的西区暂时挪到一起,组成一个临时社区。在这个社区里,大家可以自由交流,但同时给他们贴上标签(掩码),规定来自 A 城的人不能和来自 C、D 城的人说话,只能和同来自 A 城或来自 B 城的人说话。交流结束后,再用魔法把大家送回原位。
一个 Swin Transformer Block 通常由 W-MSA 和 SW-MSA 成对出现:
- Layer : W-MSA
- Layer : SW-MSA
这样交替进行,保证了在所有层中既有高效的计算,又有信息的充分交互。
代码实现
下面是一个 PyTorch 实现,演示了窗口划分、循环移位和最重要的 注意力掩码生成 过程。
1import torch2import torch.nn as nn3import torch.nn.functional as F45def window_partition(x, window_size):6 """7 将特征图划分为窗口。8 Args:9 x (torch.Tensor): 输入特征图,形状为 (B, H, W, C)。10 window_size (int): 窗口的边长。1112 Returns:13 torch.Tensor: 划分后的窗口,形状为 (num_windows*B, window_size, window_size, C)。14 """15 B, H, W, C = x.shape16 # 为什么 reshape 成 (B, H//M, M, W//M, M, C)? -> 为了将 H, W 维度拆分成窗口网格和窗口内坐标17 x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)18 # 为什么 permute 成 (B, H//M, W//M, M, M, C)? -> 为了将窗口网格的维度放在一起,方便后续合并19 windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()20 # 为什么 view 成 (B * num_windows, M, M, C)? -> 将所有窗口展平到 batch 维度,以便进行批量的注意力计算21 windows = windows.view(-1, window_size, window_size, C)22 return windows2324def window_reverse(windows, window_size, H, W):25 """26 将窗口还原为特征图。27 Args:28 windows (torch.Tensor): 划分后的窗口,形状为 (num_windows*B, window_size, window_size, C)。29 window_size (int): 窗口的边长。30 H (int): 原始特征图的高度。31 W (int): 原始特征图的宽度。3233 Returns:34 torch.Tensor: 还原后的特征图,形状为 (B, H, W, C)。35 """36 B = int(windows.shape[0] / (H * W / window_size / window_size))37 # 为什么 view 成 (B, H//M, W//M, M, M, C)? -> 这是 window_partition 中 permute 操作的逆过程38 x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)39 # 为什么 permute 成 (B, H//M, M, W//M, M, C)? -> 这是 window_partition 中 view 操作的逆过程40 x = x.permute(0, 1, 3, 2, 4, 5).contiguous()41 # 为什么 view 成 (B, H, W, C)? -> 最终合并所有维度,恢复原始特征图形状42 x = x.view(B, H, W, -1)43 return x4445def create_attention_mask(H, W, window_size, shift_size, device):46 """47 为 SW-MSA 创建注意力掩码。48 """49 # 1. 创建一个图像坐标网格,标记每个像素属于哪个子区域50 # 为什么用arange和view? -> 高效生成一个从0到N-1的标签图像,用于区分不同的移位区域51 img_mask = torch.zeros((1, H, W, 1), device=device) # 1 H W 152 h_slices = (slice(0, -window_size),53 slice(-window_size, -shift_size),54 slice(-shift_size, None))55 w_slices = (slice(0, -window_size),56 slice(-window_size, -shift_size),57 slice(-shift_size, None))58 cnt = 059 for h in h_slices:60 for w in w_slices:61 img_mask[:, h, w, :] = cnt62 cnt += 16364 # 2. 对标签图像进行窗口划分65 mask_windows = window_partition(img_mask, window_size) # (num_windows, M, M, 1)66 mask_windows = mask_windows.view(-1, window_size * window_size) # (num_windows, M*M)6768 # 3. 生成注意力掩码69 # 为什么用 unsqueeze? -> 利用广播机制,高效计算出 (M*M, M*M) 的掩码矩阵70 # 如果两个像素的标签不同(x != y),则它们不应该相互通信71 attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # (num_windows, M*M, M*M)72 # 为什么用 0 和 -100? -> 相同区域的token对,掩码值为0,不影响;不同区域的,掩码值为-100,softmax后权重接近073 attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))7475 return attn_mask7677# --- 演示 ---78if __name__ == '__main__':79 # 定义超参数80 B, H, W, C = 2, 14, 14, 96 # 假设输入特征图尺寸,H, W 必须是 window_size 的整数倍81 window_size = 782 shift_size = window_size // 28384 # 创建一个假的输入特征图85 x = torch.randn(B, H, W, C)86 print(f"输入特征图形状: {x.shape}")8788 # --- 1. W-MSA (常规窗口注意力) ---89 # 不需要移位,也不需要掩码90 print("\n--- W-MSA (常规窗口) ---")91 windows = window_partition(x, window_size)92 print(f"划分后窗口形状: {windows.shape}") # (B * num_windows, M, M, C)93 # 在这里可以进行窗口内的自注意力计算...94 reversed_x = window_reverse(windows, window_size, H, W)95 print(f"还原后特征图形状: {reversed_x.shape}")96 assert (reversed_x == x).all(), "W-MSA 还原失败"9798 # --- 2. SW-MSA (移位窗口注意力) ---99 print("\n--- SW-MSA (移位窗口) ---")100 # a. 循环移位101 # 为什么用负的 shift_size? -> torch.roll 的正值是向右/下移动,论文中的移位是向左/上,所以用负值102 shifted_x = torch.roll(x, shifts=(-shift_size, -shift_size), dims=(1, 2))103 print(f"循环移位后形状: {shifted_x.shape}")104105 # b. 在移位后的图上进行窗口划分106 shifted_windows = window_partition(shifted_x, window_size)107 print(f"移位后划分窗口形状: {shifted_windows.shape}")108109 # c. 创建并应用注意力掩码110 attn_mask = create_attention_mask(H, W, window_size, shift_size, device=x.device)111 print(f"生成的注意力掩码形状: {attn_mask.shape}") # (num_windows, M*M, M*M)112 # 在实际计算中,这个 mask 会被加到 attention scores 上113 # e.g., attn_scores = attn_scores.view(...) + attn_mask.unsqueeze(0)114115 # d. 逆向循环移位116 # 为什么用正的 shift_size? -> 为了恢复原始位置117 reversed_shifted_x_content = window_reverse(shifted_windows, window_size, H, W)118 reversed_x = torch.roll(reversed_shifted_x_content, shifts=(shift_size, shift_size), dims=(1, 2))119 print(f"SW-MSA 最终还原后形状: {reversed_x.shape}")120 assert (reversed_x == x).all(), "SW-MSA 还原失败"121 print("\n所有流程验证通过!")
工程实践
- 使用场景: Swin
Transformer作为一种通用的视觉骨干网络,被广泛应用于各种视觉任务,并取得了 SOTA (State-of-the-Art) 的性能。- 图像分类: 在 ImageNet 上表现出色。
- 目标检测: 作为 Faster R-CNN, Mask R-CNN, Cascade R-CNN 等检测器的骨干网络。
- 语义分割: 作为 UperNet, Mask2Former 等分割模型的骨干网络。
- 超参数选择:
window_size(M): 论文中固定为 7。这是一个关键的权衡点。更大的窗口意味着更大的感受野和更强的建模能力,但计算量 () 和显存占用也会增加。在实际应用中,7 是一个经过验证的、效果与效率俱佳的选择。shift_size: 通常设置为window_size // 2。这个选择保证了上一层中相邻的窗口,在下一层移位后有重叠部分,从而能够交换信息。
- 性能 / 显存 / 吞吐:
- 优势: 线性复杂度使其能够轻松处理高分辨率图像(如 224x224, 384x384),而不会像
ViT那样导致显存爆炸。这对于目标检测和分割等下游任务至关重要。 - 吞吐: 循环移位和掩码生成虽然巧妙,但相比于纯粹的卷积操作,会引入一些额外的开销和同步点。但在 GPU 上,这些操作都经过了高度优化,整体吞吐量仍然非常高。
- 优势: 线性复杂度使其能够轻松处理高分辨率图像(如 224x224, 384x384),而不会像
- 常见坑和调试技巧:
- 输入尺寸: Swin
Transformer要求输入的 H 和 W 必须是window_size的整数倍。如果不是,通常需要在输入前进行 padding。 - 掩码实现: 掩码的生成和应用是 SW-MSA 的核心,也是最容易出错的地方。调试时,可以手动设置一个极小的 H, W (如 4x4) 和
window_size(如 2),然后打印出img_mask和最终的attn_mask,一步步验证其逻辑是否正确。 - 维度变换:
window_partition和window_reverse中的view,permute操作非常多,很容易搞混。务必写清楚注释,并最好编写单元测试来验证其可逆性。
- 输入尺寸: Swin
常见误区与边界情况
-
误区一: "Swin
Transformer就是ViT的局部注意力版本"- 不完全正确。除了窗口化注意力,Swin 的另一个核心是 层级化设计 (Hierarchical Design)。它通过 Patch Merging 层,在网络加深的过程中,逐渐减小特征图的空间分辨率、增加通道数(如 224x224 -> 56x56 -> 28x28 -> 14x14 -> 7x7)。这使得 Swin 能像 CNN (如 ResNet) 一样产生多尺度的特征图,方便接入各种下游任务的 FPN (Feature Pyramid Network) 等结构。
ViT则自始至终保持固定的 token 数量和分辨率。
- 不完全正确。除了窗口化注意力,Swin 的另一个核心是 层级化设计 (Hierarchical Design)。它通过 Patch Merging 层,在网络加深的过程中,逐渐减小特征图的空间分辨率、增加通道数(如 224x224 -> 56x56 -> 28x28 -> 14x14 -> 7x7)。这使得 Swin 能像 CNN (如 ResNet) 一样产生多尺度的特征图,方便接入各种下游任务的 FPN (Feature Pyramid Network) 等结构。
-
误区二: "移位窗口就是把窗口的起始坐标移动一下"
- 这是对 SW-MSA 的朴素理解。如原理部分所述,直接移动会导致窗口大小不一,效率低下。Swin 的精髓在于使用 循环移位 + 掩码 的技巧,在保持高效批处理(所有窗口大小均为 M x M)的前提下,等效地实现了移位窗口的功能。
-
误区三: "循环移位会污染特征"
- 不会。因为注意力掩码的存在,被循环移位“错误地”拼接到一起的区域,其 token 之间的注意力权重被强制置为 0。计算完成后,又通过逆向循环移位恢复了原始的排列。整个过程只是一个为了计算效率的“障眼法”,并不会在逻辑上污染特征。
-
面试追问:
- 问: Swin
Transformer如何构建全局感受野? - 答: 通过两个机制。第一,SW-MSA 在相邻的
TransformerBlock 之间实现了局部窗口的信息交换,感受野逐层扩大。第二,Patch Merging 层会降采样,将 2x2 的 patch 合并为一个,这使得在更深层网络中,一个 token 代表了原始图像中更大的区域,从而快速扩大感受野。两者结合,使得网络深层的 token 拥有了全局感受野。 - 问: 为什么不直接用更大的卷积核,或者空洞卷积来扩大感受野?
- 答: 卷积的权重是静态的、与输入无关的,其感受野扩大方式是固定的。而 Swin
Transformer的自注意力机制是动态的,权重是根据输入内容(Query, Key)动态计算的,可以对窗口内的信息进行更灵活、更有选择性的聚合。即使在同一个窗口内,模型也能学到关注哪些 token,忽略哪些 token。这是卷积难以做到的。 - 问: 如果输入图像尺寸不能被
window_size整除怎么办? - 答: 官方实现和通常的做法是在送入网络前,对图像的右侧和下侧进行 padding,使其尺寸满足要求。计算完成后,再将 padding 部分裁掉。
- 问: Swin