AIM / AIMv2 自回归视觉预训练?
核心概念
AIM (Autoregressive Image Models) 是一种针对视觉 Transformer (ViT) 的自监督预训练框架。其核心思想借鉴了自然语言处理中的自回归模型(如 GPT),将图像预训练任务构建为一个“预测未来”的过程。具体来说,AIM 将图像的一部分(例如,上半部分图像块)作为上下文(“过去”),并训练模型去自回归地预测剩余被遮蔽部分(“未来”)的视觉特征。AIM 不直接预测像素值,而是预测由一个独立的、预训练好的“视觉分词器”(Target Model,如 CLIP 的图像编码器)所提取的特征表示,这使得模型能专注于学习更高层次的语义信息。
🍎 AIMv2 架构原理图
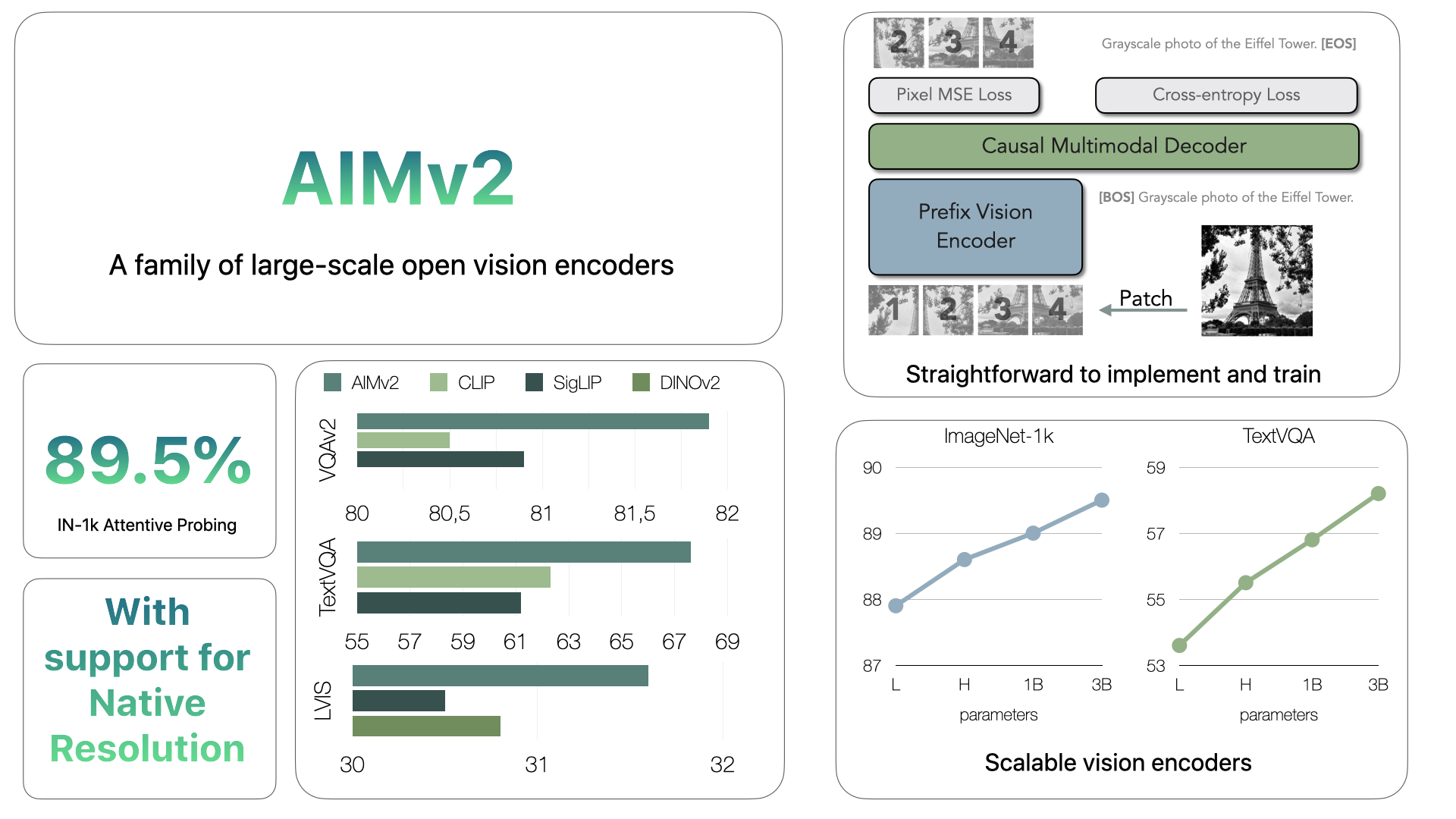
图来自 apple/ml-aim 官方仓库 README。AIMv2 (Fini et al. 2024, arxiv 2411.14402) 把 AIM 升级为多模态自回归预训练:视觉 + 文本 token 联合输入,causal mask 让模型同时预测下一个视觉 patch 和下一个文本 token。等于把 GPT-style autoregressive 训练完全推到 vision-language。
AIM v1 → AIMv2 关键差异
| AIM v1 (2024-01) | AIMv2 (2024-11) | |
|---|---|---|
| 训练数据 | 纯图像 (DFN-2B+) | 图像 + caption 配对 (DFN-CLIP scale) |
| 预测目标 | 下一个 patch 的 latent feature | 下一个 patch + 下一个 text token |
| 损失 | L2 in feature space | 视觉端 L2 + 文本端 CE |
| 下游表现 | linear probe 接近 contrastive | linear probe + zero-shot retrieval 双 SOTA |
| 对 VLM 的意义 | 视觉塔候选 | 直接可做 LMM 的初始化 |
AIM v1 论文原图见 arxiv 2401.08541 Figure 2。仓库 v1 子目录未单独发布 figure 资源。
📄 AIMv2 paper · arxiv 2411.14402 → · 💻 apple/ml-aim 代码 →
原理与推导
AIM 的核心在于其独特的预训练任务设置,它将掩码图像建模(Masked Image Modeling)与自回归预测相结合。
1. 整体流程
给定一张输入图像 ,其预训练过程如下:
- 图像分块 (Patchify): 将图像 分割成 个不重叠的图像块(patches)序列 。
- 目标生成 (Target Generation): 使用一个冻结的、预训练好的目标编码器 (例如
CLIPViT),对所有图像块 进行编码,得到目标特征序列 ,其中 。这些特征是模型需要预测的“答案”。 - 掩码策略 (Masking): 采用一种特定的策略将图像块序列分为两部分:可见块集合 和被掩码块集合 。AIM 采用一种简单的块状掩码(Block-wise Masking),例如,保留前 50% 的块作为可见块,遮蔽后 50% 的块。这种策略天然地定义了“过去”(可见区)和“未来”(掩码区)。
- 自回归预测 (Autoregressive Prediction):
- 将可见块序列 输入到待训练的
ViT模型 中,得到其上下文表示。 - 模型 的任务是基于 的信息,预测出被掩码块 对应的目标特征 。
- 将可见块序列 输入到待训练的
2. 数学公式与推导
从概率角度看,AIM 的目标是最大化在给定可见块条件下,被掩码块目标特征的对数似然:
这里的“自回归”体现在 的分解上。如果严格按照时序自回归,预测顺序很重要:
然而,在 AIM 的原始实现中,为了计算效率,它做了一个简化。它并非逐个生成掩码块的特征,而是并行地预测所有掩码块的特征。其“自回归”性质主要体现在信息流的单向性上:可见区的信息可以流向掩码区,但反之不行。这通过块状掩码策略得以实现。
因此,实际优化的损失函数是一个回归损失,通常是均方误差(MSE Loss),计算模型预测值与真实目标特征之间的差距:
其中 表示模型基于可见块 对第 个掩码块特征的预测,而 是由目标编码器生成的真实特征。
AIMv2 的改进
AIMv2 引入了多尺度和分层预测的思想,使其学习的表示更具层次性。
- 多尺度目标: 目标编码器 不再只提供最后一层的特征,而是提供多个中间层的特征。例如,浅层特征捕捉局部纹理,深层特征捕捉全局语义。
- 分层预测: 待训练的模型 被设计成一个分层结构,其浅层被训练去预测目标编码器的浅层特征,深层去预测深层特征。这强制模型在不同层级学习不同尺度的信息,提升了表示的质量和泛化能力。
算法复杂度
- 时间复杂度: 主要由
ViT中的自注意力机制决定。对于 个可见块和维度为 的模型,编码器的时间复杂度为 。预测阶段的复杂度取决于具体实现,但总体上与ViT的标准计算量级相当。 - 空间复杂度: 。
直观解释
可以把 AIM 想象成一个“看图填空”的画家。面试官先给画家看一幅画的上半部分(),然后要求他补全下半部分()。但不同于要求他画出每个像素(像 MAE),面试官给了他一个更高维度的要求:你补全的画的每个局部,其“艺术风格”和“语义内容”(由 CLIP 模型定义的特征 )必须和原作一模一样。这种方式迫使画家不仅要学习模仿,更要理解图像的结构、内容和语义。
代码实现
下面是一个使用 PyTorch 实现的 AIM 核心逻辑的简化示例。我们将使用 timm 库来获取一个 ViT 模型作为主干,并创建一个 mock 的目标模型。
1import torch2import torch.nn as nn3from timm.models.vision_transformer import VisionTransformer45# 1. 定义一个 Mock 的目标模型 (Target Model)6# 在真实场景中,这会是一个预训练好的、冻结的强大模型,如 CLIP ViT-L/147class MockTargetModel(nn.Module):8 def __init__(self, patch_size=16, embed_dim=768):9 super().__init__()10 # 目标模型也使用一个ViT结构,但它是被冻结的11 self.model = VisionTransformer(patch_size=patch_size, embed_dim=embed_dim, depth=12, num_heads=12)12 # 假设这个模型已经预训练好了,设为评估模式并冻结参数13 self.eval()14 for param in self.parameters():15 param.requires_grad = False1617 def forward(self, x):18 # 为什么这样做:目标模型的作用是为每个图像块生成一个高质量的特征表示。19 # 我们只取其输出的特征,不关心分类头。20 # forward_features方法通常返回[B, N, D]的块特征21 return self.model.forward_features(x)2223# 2. 定义 AIM 模型24class AIM(nn.Module):25 def __init__(self, patch_size=16, embed_dim=768, depth=12, num_heads=12):26 super().__init__()27 # 为什么这样做:这是我们要训练的主干模型。28 self.encoder = VisionTransformer(patch_size=patch_size, embed_dim=embed_dim, depth=depth, num_heads=num_heads)2930 # 为什么这样做:预测头用于将ViT输出的维度映射到目标特征的维度。31 # 在这个例子中,维度相同,但保留这个结构更具通用性。32 self.predictor = nn.Linear(embed_dim, embed_dim)3334 # 为什么这样做:损失函数使用MSE来计算预测特征和目标特征之间的L2距离。35 self.loss_fn = nn.MSELoss()3637 def forward(self, x, target_model, mask_ratio=0.5):38 # x: 输入图像, [B, C, H, W]3940 # --- 步骤 1: 掩码策略 ---41 # 为什么这样做:这是AIM的核心机制之一,通过块状掩码定义“过去”和“未来”。42 # ViT内部会将[B, C, H, W]的图像转换为[B, N, D]的块嵌入。N = (H/patch_size) * (W/patch_size)。43 # 我们在这里模拟这个过程来确定要掩码的块。44 num_patches = self.encoder.patch_embed.num_patches45 num_masked = int(num_patches * mask_ratio)46 num_visible = num_patches - num_masked4748 # 随机生成掩码索引,但为了简单和复现AIM的块状掩码,我们使用固定的块状掩码49 # 假设块是按光栅顺序排列的50 visible_indices = torch.arange(0, num_visible)51 masked_indices = torch.arange(num_visible, num_patches)5253 # --- 步骤 2: 生成目标特征 ---54 with torch.no_grad():55 # 为什么这样做:目标特征是预先计算好的“真值”,整个过程不应有梯度流向目标模型。56 all_target_features = target_model(x) # [B, N, D]57 target_features_for_masked = all_target_features[:, masked_indices, :] # [B, num_masked, D]5859 # --- 步骤 3: 前向传播 ---60 # 为什么这样做:ViT编码器只处理可见的图像块,这是自监督学习中提高效率的关键。61 # timm的ViT没有直接提供仅处理部分块的接口,我们通过手动选择块嵌入来模拟62 x_patches = self.encoder.patch_embed(x) # [B, N, D]63 cls_token = self.encoder.cls_token.expand(x.shape[0], -1, -1)64 x_patches = torch.cat((cls_token, x_patches), dim=1)6566 # 添加位置编码67 x_patches = x_patches + self.encoder.pos_embed6869 # 只选择可见块送入Transformer编码器70 # 注意:timm ViT的pos_embed包含了cls_token的位置,所以索引要+171 visible_patches = x_patches[:, [0] + (visible_indices + 1).tolist(), :]7273 # 编码器处理可见块74 encoded_features = self.encoder.blocks(visible_patches)75 encoded_features = self.encoder.norm(encoded_features) # [B, 1+num_visible, D]7677 # --- 步骤 4: 预测掩码块特征 ---78 # 为什么这样做:模型需要从可见块的上下文中推断出被遮蔽块的信息。79 # 这里简化处理,使用[CLS] token的输出来预测所有被遮蔽的块。80 # 更复杂的实现可能会使用专门的decoder或query token。81 cls_output = encoded_features[:, 0, :] # [B, D]8283 # 为了预测多个掩码块,我们可以重复CLS token或者使用更复杂的机制84 # 这里我们简单地让一个线性层从CLS token预测所有掩码块85 predicted_features = self.predictor(cls_output).unsqueeze(1).repeat(1, num_masked, 1) # [B, num_masked, D]8687 # --- 步骤 5: 计算损失 ---88 loss = self.loss_fn(predicted_features, target_features_for_masked)8990 return loss, predicted_features, target_features_for_masked9192# --- 运行示例 ---93if __name__ == '__main__':94 # 初始化模型95 target_model = MockTargetModel()96 aim_model = AIM()9798 # 创建伪数据99 dummy_images = torch.randn(2, 3, 224, 224) # Batch size 2100101 # 执行前向传播和损失计算102 loss, _, _ = aim_model(dummy_images, target_model, mask_ratio=0.5)103104 print(f"AIM Pre-training Loss: {loss.item()}")105106 # 验证梯度只在AIM模型中107 print("\nAIM Model Parameters Requiring Gradients:")108 for name, param in aim_model.named_parameters():109 if param.requires_grad:110 print(name)111112 print("\nTarget Model Parameters Requiring Gradients:")113 has_grad = False114 for name, param in target_model.named_parameters():115 if param.requires_grad:116 print(name)117 has_grad = True118 if not has_grad:119 print("None (as expected)")
工程实践
- 使用场景: AIM预训练出的模型是强大的视觉特征提取器。它们在各种下游任务中表现出色,尤其是需要理解图像空间关系和密集预测的任务,如:
- 图像分类 (Image Classification): 在ImageNet等数据集上进行微调。
- 目标检测 (Object Detection): 作为Faster R-CNN, Mask R-CNN等检测器的骨干网络。
- 语义分割 (Semantic Segmentation): 作为U-Net, DeepLab等分割模型的编码器。
- 超参数选择:
- 目标模型: 这是最重要的选择之一。通常,目标模型越强大(如
CLIPViT-L/14),提供的监督信号质量越高,预训练效果越好。但这也意味着更大的计算开销来生成目标。 - 掩码率 (Mask Ratio): AIM论文中发现50%到75%的掩码率效果较好。较高的掩码率使任务更难,迫使模型学习更鲁棒的表示。
- 目标特征归一化: 目标模型(如
CLIP)输出的特征向量可能没有固定的范围。在计算损失之前,对目标特征和预测特征进行L2归一化,可以使训练过程更稳定。 - 学习率与优化器: 通常使用AdamW优化器,配合cosine学习率衰减策略。由于是自监督学习,预训练过程通常需要较长的训练周期(数百个epochs)。
- 目标模型: 这是最重要的选择之一。通常,目标模型越强大(如
- 性能/显存/吞吐的权衡:
- 预训练成本: AIM的预训练成本非常高,需要大规模无标签数据集(如ImageNet-22K, JFT-300M)和大量的TPU/GPU小时。
- 目标生成: 如果在数据加载时动态生成目标特征,会增加数据预处理的CPU/GPU负担。一种常见的优化是提前计算好所有图像的目标特征,并存储起来,但这需要巨大的磁盘空间。
- 模型大小: 更大的
ViT模型(如ViT-L, ViT-H)通常能获得更好的性能,但训练和推理的成本也更高。
- 常见坑和调试技巧:
- 损失不下降: 检查目标特征是否正确归一化。检查学习率是否过高或过低。
- 可视化是关键: 尽管AIM预测的是特征,但可以通过一个“解码器”(例如,找到特征空间中最近邻的真实图像块)来可视化模型的预测结果。如果模型能重建出有意义的结构,说明训练在正确的轨道上。
- 模型实现细节:
ViT的实现细节(如位置编码、LayerNorm的位置)对最终性能有影响。尽量与经过验证的开源实现(如timm)保持一致。
常见误区与边界情况
- 误区1: AIM预测像素值
- 错误点: 认为AIM像MAE(Masked Autoencoders)一样,直接重建图像的原始像素。
- 纠正: AIM预测的是由一个强大教师模型(如
CLIP)提取的抽象特征。这使得模型不必浪费容量去拟合高频、低语义的像素细节,而是专注于学习与教师模型对齐的语义概念。
- 误区2: AIM与BEiT/MAE没有区别
- 错误点: 将所有掩码图像建模方法混为一谈。
- 纠正:
- AIM vs. MAE: AIM预测特征,MAE预测像素。AIM是自回归框架,MAE是并行解码。
- AIM vs. BEiT: AIM的目标是连续特征,BEiT的目标是离散的视觉词元(token)(来自dVAE)。AIM的框架类似GPT(自回归),BEiT的框架类似
BERT(掩码语言模型)。
- 误区3: “自回归”意味着逐像素/逐块的缓慢生成
- 错误点: 将其与文本生成中的严格串行过程等同。
- 纠正: AIM的“自回归”更多是概念上的,体现在信息流的单向性(从可见区到掩码区)。其实际实现(特别是块状掩码)允许对所有被掩码块进行并行预测,从而保持了计算效率。它是一种区域级别(region-level)的自回归。
- 边界情况与面试追问:
- 问: 如果目标模型很差会怎么样?
- 答: 预训练的效果会大打折扣。AIM的性能上限在很大程度上受限于教师模型的“知识水平”。如果教师模型本身不能很好地理解图像,它提供的目标特征就是“垃圾”,学生模型自然也学不到有用的东西(Garbage in, garbage out)。
- 问: 为什么不直接用一个随机初始化的模型当目标编码器?
- 答: 这会导致“盲人引路”的问题。一个未经训练的模型输出的特征是随机且无意义的,无法提供有效的学习信号。整个训练过程可能会崩溃或学到平凡解。
- 问: AIMv2的多尺度设计有什么好处?
- 答: 它迫使模型在不同深度学习不同层次的抽象。浅层负责重建纹理细节(对应教师模型的浅层特征),深层负责理解全局结构(对应教师模型的深层特征)。这使得最终学到的特征表示更加丰富和全面,对下游任务的适应性更强。
- 问: 如果目标模型很差会怎么样?
- BERT: Pre-training of Deep Bidirectional Transformers· 2018看站内总结 →
Masked Language Modeling + 双向 Transformer Encoder——预训练+微调范式的奠基之作。
- CLIP: Learning Transferable Visual Representations· 2021看站内总结 →
4 亿图文对 + 对比学习——零样本图像分类能和监督训练的 ResNet 匹敌。
- MAE: Masked Autoencoders Are Scalable Vision Learners· 2021看站内总结 →
BERT-for-vision:mask 掉 75% patch、不对称 encoder/decoder、像素级重建——把 ViT 的 SSL 推到生产可用。