RADIO / AM-RADIO 多 teacher 蒸馏统一视觉 backbone?
好的,我们来深入剖析 RADIO / AM-RADIO 这一先进的多教师知识蒸馏框架。
核心概念
RADIO (Robust Aggregation of Diverse Oracles) 是一种多教师知识蒸馏(Knowledge Distillation, KD)框架。其核心思想是,当面对多个不同架构、不同训练数据的“教师”模型时,不再简单地平均它们的输出,而是训练一个“学生”模型,让它学会为每一个输入样本动态地预测一组权重,然后用这组权重来加权融合所有教师的输出。这个融合后的结果将作为一个更优质、更鲁棒的“软标签”来指导学生模型的学习。AM-RADIO (Attention-Masked RADIO) 是其升级版,将权重从单个向量扩展为空间注意力图,使得模型可以为图像的不同区域分配不同的教师权重,尤其适用于稠密预测任务。
🛰 AM-RADIO 多 teacher 蒸馏原理图
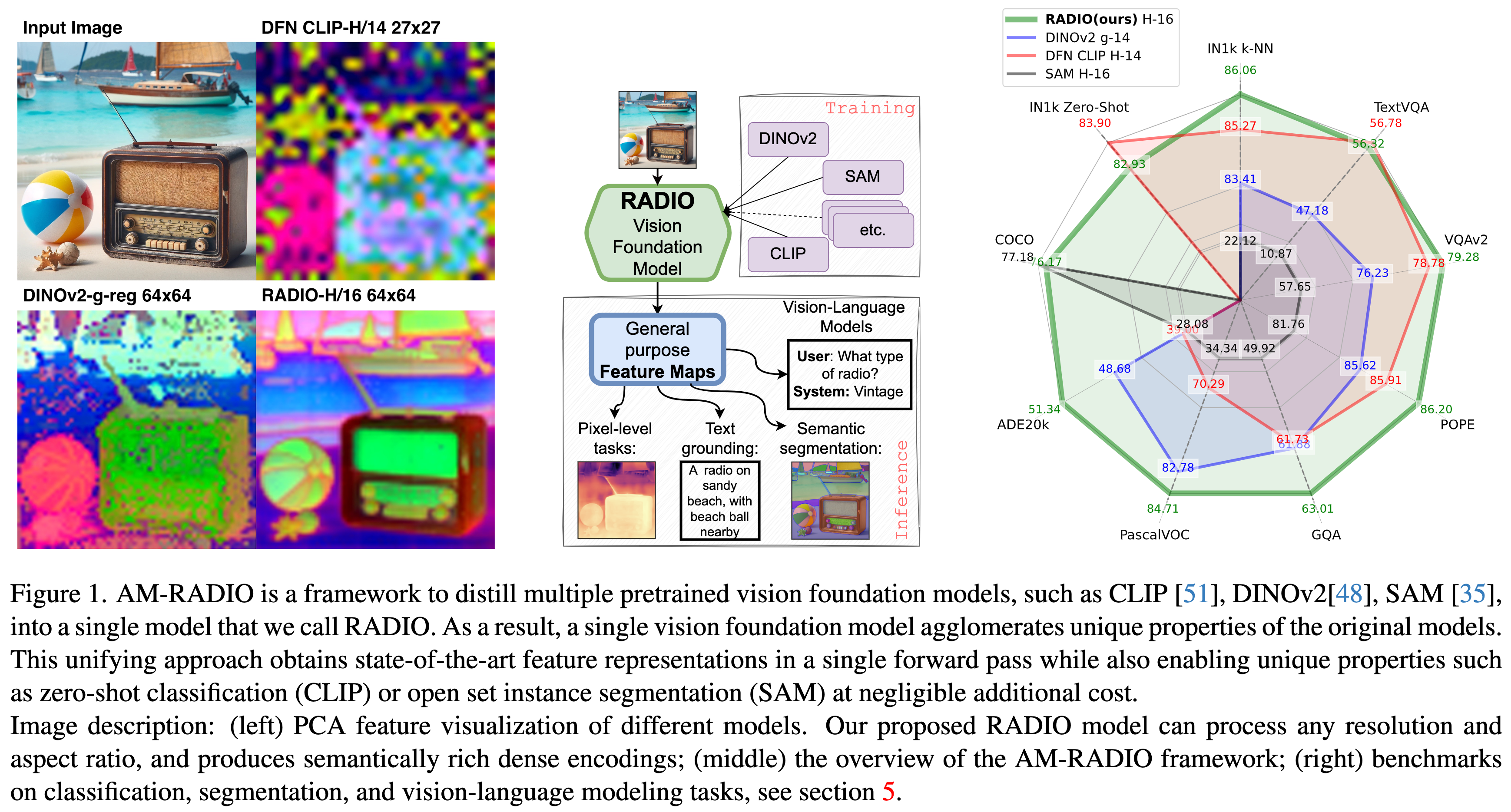
图来自 NVlabs/RADIO 官方仓库(NVIDIA, AM-RADIO: Agglomerative Vision Foundation Model · arxiv 2312.06709, CVPR 2024)。一个 student backbone 同时蒸馏多个不同 teacher(CLIP / DINOv2 / SAM 等),每个 teacher 在自己擅长的能力维度提供监督——student 输出端用多 head 分别匹配各 teacher。推理时只跑 student,部署成本 = 单 backbone,能力 = 多个 foundation model 综合。
RADIO 演化(截止 2025)
| 版本 | 主要改动 | Paper |
|---|---|---|
| AM-RADIO (2023-12 / CVPR 2024) | 提出多 teacher 蒸馏框架,三师傅 CLIP + DINOv2 + SAM | arxiv 2312.06709 |
| PHI Standardization (2024-10) | 引入特征标准化,让多 teacher 输出统一到同一空间,提升蒸馏稳定性 | arxiv 2410.01680 |
| RADIOv2.5 (2024-12 / CVPR 2025) | 多分辨率训练、mode switching(不同分辨率切换不同 teacher 权重) | arxiv 2412.07679 |
| FeatSharp (2025 / ICML 2025) | 改进 dense feature 质量 | arxiv 2502.16025 |
| CRADIOv4 (2025) | 最新一代,参数效率更高 | arxiv 2601.17237 |
📄 AM-RADIO paper · CVPR 2024 → · 💻 NVlabs/RADIO 代码 →
原理与推导
为了理解 RADIO,我们首先从标准知识蒸馏出发。
1. 标准知识蒸馏 (Standard KD)
假设有一个教师模型 和一个学生模型 。对于输入 ,它们的 Logits 输出分别为 和 。KD 的损失函数通常包含两部分:
- 硬标签损失 (Hard Label Loss):学生模型与真实标签 之间的交叉熵损失。 其中 是学生的预测概率。
- 软标签损失 (Soft Label Loss):学生模型的输出概率分布与教师模型的软化后概率分布之间的 KL 散度。 其中 是经过温度 软化后的概率分布。 会平滑概率分布,让模型关注类别间的相对关系,即所谓的“暗知识”。
总损失为 。
2. 从朴素多教师到 RADIO
当有 个教师 时,最朴素的方法是平均它们的 Logits 或概率: 然后用 或 作为唯一的教师信号进行标准 KD。
动机缺陷:这种平均策略假设所有教师对所有样本的贡献都相同,这显然不合理。某些教师可能在特定类型的图像上表现更好。
RADIO 的解决方案:引入一个“门控网络”(Gating Network),让学生模型自己学会判断“听谁的”。
-
模型结构:学生模型 除了主干网络 (输出特征)和分类头(输出 Logits )外,还增加一个轻量级的门控头 。 的输入通常是 提取的特征,输出是一个 维的向量,对应 个教师的权重。
-
混合概率分布:对于输入 ,门控头输出 ,通过
softmax归一化得到每个教师的权重 : 教师们的概率分布 被这些权重加权混合,形成一个更优的“混合教师”概率分布 : -
RADIO 损失函数:最终的蒸馏目标是让学生自身的预测分布 逼近这个动态生成的混合教师分布 。 完整的训练损失通常还包括学生与真实标签的交叉熵损失: 其中 是超参数,用于平衡两项损失。
直观解释:RADIO 框架迫使学生模型学习一个元认知能力(meta-cognition):它不仅要学会分类,还要学会评估在当前样本上,哪位老师的“意见”更值得采纳。梯度会同时流向主干网络和门控网络,协同优化分类能力和“决策”能力。
3. AM-RADIO: 空间感知的混合
动机:对于高分辨率图像或稠密预测任务(如分割、检测),图像的不同区域可能适合由不同教师来指导。例如,一个教师可能擅长识别纹理,另一个擅长识别物体轮廓。
AM-RADIO 的解决方案:将门控从一个全局向量升级为一个空间注意力图。
-
模型结构:学生模型的门控头 不再输出一个向量,而是输出一个与特征图空间维度一致的张量,形状为 ( 是特征图高宽, 是教师数量)。
-
空间混合权重:在每个空间位置 上,沿着教师维度(channel 维)进行
softmax,得到该位置上对 个教师的权重分布 。 -
特征级蒸馏:AM-RADIO 通常在特征层面进行蒸馏。假设所有教师和学生都能输出 的特征图 和 。 混合特征图 通过空间权重 对教师特征图进行加权求和: 这可以用广播和逐元素乘法高效计算。
-
AM-RADIO 损失函数:让学生的特征图 逼近这个动态混合的“超级特征图” ,通常使用 L2 损失:
复杂度分析:
- 训练时间/空间:训练时需要对所有 个教师模型执行前向传播,计算成本和显存占用是朴素单教师蒸馏的 倍。但可以通过预计算并缓存所有教师的输出(Logits 或特征)来解决,将额外开销转移到一次性的数据预处理上。
- 推理时间/空间:推理时只使用训练好的学生模型,门控头和教师模型都被丢弃。因此,推理成本与普通单模型完全相同,这是其巨大优势。
代码实现
下面是一个使用 PyTorch 实现的简化版 RADIO 和 AM-RADIO 概念验证代码。
1import torch2import torch.nn as nn3import torch.nn.functional as F45# --- 1. 定义模型 ---67class SimpleTeacher(nn.Module):8 """一个简单的教师模型,用于演示"""9 def __init__(self, name):10 super().__init__()11 self.name = name12 self.conv1 = nn.Conv2d(3, 16, 3, padding=1)13 self.conv2 = nn.Conv2d(16, 32, 3, padding=1)14 self.pool = nn.AdaptiveAvgPool2d((1, 1))15 self.fc = nn.Linear(32, 10) # 假设10分类1617 def forward(self, x):18 # 提取特征19 features = F.relu(self.conv1(x))20 features = self.conv2(features) # (B, 32, H, W)21 # 计算logits22 pooled_features = self.pool(features).view(x.size(0), -1)23 logits = self.fc(pooled_features)24 return logits, features2526class StudentWithGating(nn.Module):27 """带门控头的学生模型"""28 def __init__(self, num_teachers):29 super().__init__()30 # 主干网络 (与教师类似但可以更小)31 self.conv1 = nn.Conv2d(3, 8, 3, padding=1)32 self.conv2 = nn.Conv2d(8, 16, 3, padding=1)33 self.pool = nn.AdaptiveAvgPool2d((1, 1))34 self.fc = nn.Linear(16, 10) # 分类头3536 # --- 门控头 ---37 # RADIO的门控头:从全局特征预测权重38 self.radio_gating_head = nn.Linear(16, num_teachers)3940 # AM-RADIO的门控头:从特征图预测空间权重图41 self.am_radio_gating_head = nn.Conv2d(16, num_teachers, kernel_size=1)4243 def forward(self, x):44 # 提取特征45 features = F.relu(self.conv1(x))46 features = self.conv2(features) # (B, 16, H, W)4748 # 计算学生自己的logits49 pooled_features = self.pool(features).view(x.size(0), -1)50 student_logits = self.fc(pooled_features)5152 # 计算门控输出53 radio_gating_out = self.radio_gating_head(pooled_features) # (B, num_teachers)54 am_radio_gating_out = self.am_radio_gating_head(features) # (B, num_teachers, H, W)5556 return student_logits, features, radio_gating_out, am_radio_gating_out5758# --- 2. 定义损失函数 ---5960def radio_loss_fn(student_logits, student_gating_out, teacher_logits_list, temperature):61 """62 计算RADIO的蒸馏损失 (KL散度)63 """64 # 为什么这样做: 首先获取所有教师的软化后概率分布65 teacher_probs_list = [F.softmax(logits / temperature, dim=-1) for logits in teacher_logits_list]66 # (num_teachers, B, num_classes) -> (B, num_teachers, num_classes)67 teacher_probs = torch.stack(teacher_probs_list, dim=1)6869 # 为什么这样做: 计算学生预测的、用于混合教师的权重70 gating_weights = F.softmax(student_gating_out, dim=-1) # (B, num_teachers)7172 # 为什么这样做: 根据权重混合教师的概率分布,形成最终的软目标73 # (B, num_teachers, 1) * (B, num_teachers, num_classes) -> (B, num_teachers, num_classes)74 # sum over dim=1 -> (B, num_classes)75 mixed_teacher_prob = torch.sum(gating_weights.unsqueeze(-1) * teacher_probs, dim=1)7677 # 为什么这样做: 计算学生自己的软化后对数概率分布78 student_log_prob = F.log_softmax(student_logits / temperature, dim=-1)7980 # 为什么这样做: 计算KL散度。PyTorch的kl_div期望(log_prob, prob)。81 # reduction='batchmean'表示损失会对batch和类别维度求平均,更稳定。82 loss = F.kl_div(student_log_prob, mixed_teacher_prob.detach(), reduction='batchmean') * (temperature ** 2)83 return loss, gating_weights8485def am_radio_loss_fn(student_features, student_gating_map, teacher_features_list):86 """87 计算AM-RADIO的特征蒸馏损失 (MSE)88 """89 # 为什么这样做: 将教师特征列表堆叠成一个张量,方便后续计算90 # (num_teachers, B, C, H, W) -> (B, num_teachers, C, H, W)91 teacher_features = torch.stack(teacher_features_list, dim=1)9293 # 为什么这样做: 计算空间权重图,在每个像素点上对教师进行softmax94 # (B, num_teachers, H, W)95 gating_weights_map = F.softmax(student_gating_map, dim=1)9697 # 为什么这样做: 使用空间权重图混合教师的特征图98 # unsqueeze(2) -> (B, num_teachers, 1, H, W) for broadcasting99 # (B, num_teachers, 1, H, W) * (B, num_teachers, C, H, W) -> (B, num_teachers, C, H, W)100 # sum over dim=1 -> (B, C, H, W)101 mixed_teacher_features = torch.sum(gating_weights_map.unsqueeze(2) * teacher_features, dim=1)102103 # 为什么这样做: 计算学生特征与混合教师特征之间的均方误差104 loss = F.mse_loss(student_features, mixed_teacher_features.detach())105 return loss, gating_weights_map106107108# --- 3. 模拟训练流程 ---109if __name__ == '__main__':110 # --- 初始化 ---111 B, C, H, W = 4, 3, 32, 32112 NUM_CLASSES = 10113 NUM_TEACHERS = 3114 TEMPERATURE = 4.0115 LAMBDA_RADIO = 1.0116 LAMBDA_AM_RADIO = 0.5117118 # 创建虚拟数据119 dummy_images = torch.randn(B, C, H, W)120 dummy_labels = torch.randint(0, NUM_CLASSES, (B,))121122 # 创建模型123 teachers = [SimpleTeacher(name=f"T{i}") for i in range(NUM_TEACHERS)]124 student = StudentWithGating(num_teachers=NUM_TEACHERS)125126 # 冻结教师模型参数127 for teacher in teachers:128 for param in teacher.parameters():129 param.requires_grad = False130131 optimizer = torch.optim.Adam(student.parameters(), lr=1e-3)132133 # --- 前向传播 ---134 # 获取教师们的输出135 teacher_logits_list = []136 teacher_features_list = []137 for teacher in teachers:138 logits, features = teacher(dummy_images)139 teacher_logits_list.append(logits)140 teacher_features_list.append(features)141142 # 获取学生输出143 s_logits, s_features, s_radio_gating, s_am_radio_gating = student(dummy_images)144145 # --- 计算损失 ---146 # 1. 学生自己的分类损失147 ce_loss = F.cross_entropy(s_logits, dummy_labels)148149 # 2. RADIO 蒸馏损失150 radio_distill_loss, radio_weights = radio_loss_fn(s_logits, s_radio_gating, teacher_logits_list, TEMPERATURE)151152 # 3. AM-RADIO 特征蒸馏损失153 am_radio_distill_loss, am_radio_weights_map = am_radio_loss_fn(s_features, s_am_radio_gating, teacher_features_list)154155 # 总损失156 total_loss = ce_loss + LAMBDA_RADIO * radio_distill_loss + LAMBDA_AM_RADIO * am_radio_distill_loss157158 # --- 反向传播与优化 ---159 optimizer.zero_grad()160 total_loss.backward()161 optimizer.step()162163 print(f"Total Loss: {total_loss.item():.4f}")164 print(f" - CE Loss: {ce_loss.item():.4f}")165 print(f" - RADIO Loss: {radio_distill_loss.item():.4f}")166 print(f" - AM-RADIO Loss: {am_radio_distill_loss.item():.4f}")167 print("\nRADIO Gating Weights (for first sample in batch):")168 print(radio_weights[0].detach().numpy())169 print(f"\nAM-RADIO Weights Map shape: {am_radio_weights_map.shape}")
工程实践
- 使用场景:当你拥有多个预训练好的、具有不同专长的模型时,RADIO 是一个绝佳的工具。例如,你想创建一个统一的视觉骨干网络,可以融合
CLIP模型(强大的图文对齐能力)、DINO 模型(优秀的语义分割特征)、ImageNet-21K 监督预训练模型(丰富的类别知识)等。最终得到的学生模型将是一个“集大成者”,在多种下游任务上表现出色,且推理时没有额外开销。 - 超参数选择:
- 温度 (Temperature):通常取 2 到 10 之间的值。较高的温度会产生更软的概率分布,鼓励学生学习类别间的关系(暗知识)。需要根据任务和教师模型的“自信程度”进行调整。
- 损失权重 :平衡 CE 损失和蒸馏损失。通常从 1.0 开始,通过验证集效果进行网格搜索。如果学生模型在验证集上分类准确率低但蒸馏损失小,说明过于关注“模仿”而忽视了“学习”,应降低 。
- 门控网络架构:保持门控头轻量。对于 RADIO,一个简单的
nn.Linear足够。对于 AM-RADIO,一个1x1的nn.Conv2d通常是最佳选择。过于复杂的门控头会增加过拟合风险和训练难度。
- 性能/显存优化:
- 缓存教师输出:训练多教师模型最大的瓶颈是显存和计算。在训练开始前,对整个训练集进行一次前向传播,将所有教师的 Logits 和/或特征图保存到磁盘。训练时直接从磁盘加载这些预计算好的张量。这会极大地加速训练并降低显存需求,代价是占用大量磁盘空间。
- 调试技巧:
- 监控门控权重:训练过程中,一定要监控门控网络输出的权重。理想情况下,权重应该是动态变化的,反映了不同样本对不同教师的偏好。
- 权重坍缩 (Weight Collapse):如果权重很快收敛到 one-hot(例如,永远只选择第一个教师),说明门控网络可能学习得太快或教师间差异过大。可以尝试降低门控头的学习率,或在门控的
softmax中也加入温度使其平滑。 - 权重均匀化 (Weight Averaging):如果权重始终接近均匀分布(),说明门控网络没有学到有效信息。可能是输入给门控头的特征表达能力不足,或者所有教师的表现确实很相似。
常见误区与边界情况
-
误区一:RADIO 等同于模型集成(Ensemble)
- 辨析:模型集成是在推理时运行多个模型并将结果融合,这会带来数倍的计算和延迟。RADIO 是在训练时利用多个教师,将它们的集体智慧蒸馏到一个学生模型中。推理时只运行这个学生模型,成本低廉。RADIO 是一种“集成蒸馏”技术。
-
误区二:学生模型必须和教师模型架构相似
- 辨析:完全不必。学生模型可以比所有教师都小(模型压缩),也可以比所有教师都大(能力增强)。只要能对齐输出空间(Logits 或特定层特征),任何架构都可以作为学生。这是其灵活性的体现。
-
边界情况:教师模型高度同质化
- 如果所有教师模型都是用相同数据、相同架构训练出来的不同随机种子版本,它们之间的差异性会很小。在这种情况下,RADIO 的门控网络可能学不到有意义的权重,效果退化为简单的平均,优势不明显。RADIO 的威力在融合**多样性(Diverse)**的教师时才能最大化。
-
面试追问:AM-RADIO 和普通的注意力机制有什么区别?
- 回答要点:
- 目标不同:常规的自注意力(
Self-Attention)机制是在单个模型内部,让模型关注输入的不同部分(例如,图像的不同区域或序列的不同时间步)来构建更丰富的特征表示。 - 作用对象不同:AM-RADIO 的注意力机制是作用于多个外部模型(教师)之间的。它不是在问“我应该关注输入的哪个部分?”,而是在问“对于输入的这个特定部分,我应该听取哪位老师的意见?”。它的输出是一个在教师维度上的选择权重图,而不是一个加权融合后的新特征图。
- 目标不同:常规的自注意力(
- 回答要点:
-
面试追问:如果一个教师在某些样本上输出是完全错误的,RADIO 会如何处理?
- 回答要点:这是 RADIO 鲁棒性(Robust)的体现。理想情况下,门控网络会学会识别出这种情况。当一个教师给出与其他教师或真实标签差异极大的预测时,学生模型可以通过反向传播调整门控网络,降低分配给这个“胡言乱语”的教师的权重,从而在未来的相似样本上忽略它的影响。这比简单的平均策略更能抵抗坏教师的干扰。
- CLIP: Learning Transferable Visual Representations· 2021看站内总结 →
4 亿图文对 + 对比学习——零样本图像分类能和监督训练的 ResNet 匹敌。
- DINO: Emerging Properties in Self-Supervised Vision Transformers· 2021看站内总结 →
Self-distillation with no labels:学生预测教师 (EMA) 的 softmax,纯靠 multi-crop + centering + sharpening 学到能直接做分割的视觉特征。
- DINOv2: Learning Robust Visual Features without Supervision· 2024看站内总结 →
把 DINO 的 self-distillation + 142M 精挑数据 + iBOT 风格 patch-level loss 推到 ViT-g (1.1B),产出可直接用于多种下游任务的「通用视觉特征」。